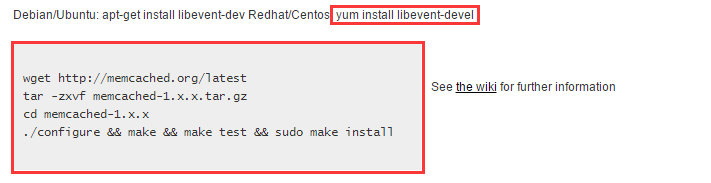
maven:
<dependency> <groupId>com.whalin</groupId> <artifactId>Memcached-Java-Client</artifactId> <version>3.0.0</version> </dependency>
CacheHelper.java
import com.whalin.MemCached.MemCachedClient;
import com.whalin.MemCached.SockIOPool;
public class CacheHelper {
/* 单例模式 */
protected static MemCachedClient mcc = new MemCachedClient();
private CacheHelper() {
}
/* 配置服务器组 */
static {
/* 定义IP地址和端口 */
String[] servers = {"121.42.151.190:11211"};
/* 设置缓存大小 */
Integer[] weights = { 2 };
/* 拿到一个连接池的实例 */
SockIOPool pool = SockIOPool.getInstance();
/* 注入服务器组信息 */
pool.setServers(servers);
pool.setWeights(weights);
/* 配置缓冲池的一些基础信息 */
pool.setInitConn(5);
pool.setMinConn(5);
pool.setMaxConn(250);
pool.setMaxIdle(1000 * 60 * 60 * 6);
/* 设置线程休眠时间 */
pool.setMaintSleep(30);
/* 设置关于TCP连接 */
pool.setNagle(false);// 禁用nagle算法
pool.setSocketConnectTO(0);
pool.setSocketTO(3000);// 3秒超时
/* 初始化 */
pool.initialize();
/* 设置缓存压缩 */
// mcc.setCompressEnable(true);
// mcc.setCompressThreshold(64 * 1024);
}
public static boolean set(String arg0, Object arg1) {
return mcc.set(arg0, arg1);
}
public static Object get(String arg0) {
return mcc.get(arg0);
}
/* 测试 */
public static void main(String[] args) {
CacheHelper.set("gogo", "gogogogo");
System.out.println(CacheHelper.get("gogo"));// gogogogo
System.out.println(CacheHelper.get("gogog"));// null
/* 如果出现都为null,检查地址和端口。端口可以到Memcached同目录配置文件看。
相关文章链接http://xhope.top/?p=413 */
}
}
输出: