JAVA写js文件,获取json数据乱码问题
解决方案,写入文件时要以UTF-8的形式写入,不然将会出现乱码
FileUtils.writeStringToFile(new File(jsFile), sb.toString(),”UTF-8“);
JAVA写js文件,获取json数据乱码问题
解决方案,写入文件时要以UTF-8的形式写入,不然将会出现乱码
FileUtils.writeStringToFile(new File(jsFile), sb.toString(),”UTF-8“);
1. 配置bean,增加spring对国际化的支持 ReloadableResourceBundleMessageSource
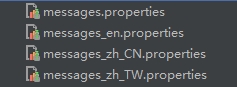
2. 资源文件 messages_zh_CN.properties
3. 使用国际化 <s:message code=”hello”/> context.getMessage(“hello”);
spring-service.xml,之前在spring-web.xml,导致获取不到bean
<bean id=”messageSource”
class=”org.springframework.context.support.ReloadableResourceBundleMessageSource”>
<property name=”basenames”>
<list>
<value>classpath:/messages</value>
</list>
</property>
<property name=”defaultEncoding” value=”UTF-8″ />
<property name=”useCodeAsDefaultMessage” value=”true”></property>
</bean>
<bean id=”localeResolver” class=”org.springframework.web.servlet.i18n.SessionLocaleResolver”>
<property name=”defaultLocale” value=”zh_CN”></property>
</bean>
spring-web.xml 语言切换的时候拦截
<mvc:interceptors>
<bean id=”localeChangeInterceptor”
class=”org.springframework.web.servlet.i18n.LocaleChangeInterceptor”>
<property name=”paramName” value=”lang” />
</bean>
</mvc:interceptors>
资源文件在resources目录下,直接在classpath下
使用:jsp:标签使用,java:上下文.getMessage()
错误分析:
1. 加载资源文件的时候,会去判断beanFactory中有没有包含bean id=”messageSource”的bean,这也是为什么ReloadableResourceBundleMessageSource类的bean的id一定要为“messageSource”。这个时候可以通过beanFactory.getBeanDefinition(“messageSource”),如果没有包含,则不走if语句,spring就没有加载资源文件,那么当你在使用<s:message code=”hello”/>
将会报错:No message found under code ‘title’ for locale ‘zh_CN’, 换句话说此错误是没有加载到bean messageSource。


2. 语言切换无效。通过地址栏http://localhost:8080/page/index.jsp?lang=en
地址栏请求是*.jsp,参照tomcat home/conf/web.xml截图
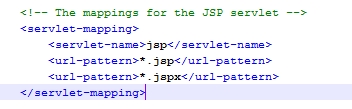
所有的*.jsp 会被tomcat容器拦截,根据servlet匹配原则,就不会走DispatcherServlet,就不会走拦截器LocaleChangeInterceptor,所以设置语言无效。
方案:
现在将切换语言的功能通过访问controller

http://localhost:8080/page/index?lang=en
让拦截LocaleChangeInterceptor去设置语言
控件:commons-fileupload-1.2.1.jar
当上传文件的时候表单,表单这个写:
<form name="" action="xx.do" method="post" enctype="multipart/form-data"> <input type="file"> <input type="text" name="username"> </form>
这个时候获取username表单参数的时候,不能用request.getParameter(“username”),这个样无论如何获取到的都是null,这句需要控件来帮助获取值。
DiskFileItemFactory factory = new DiskFileItemFactory();
ServletFileUpload upload = new ServletFileUpload(factory);
upload.setHeaderEncoding(request.getCharacterEncoding());
Map<String,String> paramMap = new HashMap<String,String>(6);
try {
List items = upload.parseRequest(req);
Iterator itr = items.iterator();
String fileName=null;
while (itr.hasNext()) {
FileItem item = (FileItem) itr.next();
if(item.isFormField()) {
String name = item.getFieldName();
String value = item.getString(request.getCharacterEncoding());
paramMap.put(name, value);
} else {
if (item.getName() != null && !item.getName().equals("")) {
fileName = item.getName();
File file = new File(RESOURCE_PATH,fileName);
item.write(file);
paramMap.put("src", fileName);
}
}
}
} catch (FileUploadException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
通过”item.isFormField()“来获取表单字段的值,同时itme.getString(request.getCharacterEncodring()).来解决字符乱码的问题。这个地方尤其要注意。
1.varchar,nvarchar,
四个类型都属于变长字符类型, varchar和varchar2的区别在与后者把所有字符都占两字节,前者只对汉字和全角等字符占两字节。 nvarchar和nvarchar2的区别和上面一样, 与上面区别在于是根据Unicode 标准所进行的定义的类型,通常用于支持多国语言类似系统的定义。
1.char
char的长度是固定的,比如说,你定义了char(20),即使你你插入abc,不足二十个字节,数据库也会在abc后面自动加上17个空格,以补足二十个字节;
char是区分中英文的,中文在char中占两个字节,而英文占一个,所以char(20)你只能存20个字母或10个汉字。
char适用于长度比较固定的,一般不含中文的情况
2.varchar/varchar2
varchar是长度不固定的,比如说,你定义了varchar(20),当你插入abc,则在数据库中只占3个字节。
varchar同样区分中英文,这点同char。
varchar2基本上等同于varchar,它是oracle自己定义的一个非工业标准varchar,不同在于,varchar2用null代替varchar的空字符串
varchar/varchar2适用于长度不固定的,一般不含中文的情况
3.nvarchar/nvarchar2
nvarchar和nvarchar2是长度不固定的
nvarchar不区分中英文,比如说:你定义了nvarchar(20),你可以存入20个英文字母/汉字或中英文组合,这个20定义的是字符数而不是字节数
nvarchar2基本上等同于nvarchar,不同在于nvarchar2中存的英文字母也占两个字节
nvarchar/nvarchar2适用于存放中文
char [ ( n ) ]
固定长度,非 Unicode 字符数据,长度为 n 个字节。n 的取值范围为 1 至 8,000,存储大小是 n 个字节。
varchar [ ( n | max ) ]
可变长度,非 Unicode 字符数据。n 的取值范围为 1 至 8,000。max 指示最大存储大小是 2^31-1 个字节。存储大小是输入数据的实际长度加 2 个字节,用于反映存储的数据的长度。所输入数据的长度可以为 0 个字符。
* 如果列数据项的大小一致,则使用 char。
* 如果列数据项的大小差异相当大,则使用 varchar。
* 如果列数据项大小相差很大,而且大小可能超过 8,000 字节,请使用 varchar(max)。
如果未在数据定义或变量声明语句中char 或 varchar 数据类型指定 n,则默认长度为 1。如果在使用 CAST 和 CONVERT 函数时char 或 varchar 数据类型未指定 n,则默认长度为 30。
当执行 CREATE TABLE 或 ALTER TABLE 时,如果 SET ANSI_PADDING 为 OFF,则定义为 NULL 的 char 列将作为 varchar 处理。
另外帮助理解的,只供参考:转自http://www.51testing.com/?uid-258885-action-viewspace-itemid-141197
也可参照学习http://ce.sysu.edu.cn/garden/dispbbs.asp?boardid=26&ID=8774&replyID=18180&skin=1
1.NULL值(空值)。
a. char列的NULL值占用存储空间。
b. varcahr列的NULL值不占用存储空间。
c. 插入同样数量的NULL值,varchar列的插入效率明显高出char列。
2.插入数据
无论插入数据涉及的列是否建立索引,char的效率都明显低于varchar。
3. 更新数据
如果更新的列上未建立索引,则char的效率低于varchar,差异不大;建立索引的话,效率较高。
4. 修改结构
a. 无论增加或是删除的列的类型是char还是varchar,操作都能较快的完成,而且效率上没有什么差异。
b. 对于增加列的宽度而言,char与varchar有非常明显的效率差异,修改varcahr列基本上不花费时间,而修改char列需要花费很长的时间。
5.数据检索
无论是否通过索引,varchar类型的数据检索略优于char的扫描。
选择char还是选择varchar的建议
1.适宜于char的情况:
a. 列中的各行数据长度基本一致,长度变化不超过50字节;
b. 数据变更频繁,数据检索的需求较少。
c. 列的长度不会变化,修改char类型列的宽度的代价比较大。
d. 列中不会出现大量的NULL值。
e. 列上不需要建立过多的索引,过多的索引对char列的数据变更影响较大。
2.适宜于varchar的情况;
a. 列中的各行数据的长度差异比较大。
b. 列中数据的更新非常少,但查询非常频繁。
c. 列中经常没有数据,为NULL值或为空值
nchar [ ( n ) ]
n 个字符的固定长度的 Unicode 字符数据。n 值必须在 1 到 4,000 之间(含)。存储大小为两倍 n 字节。
nvarchar [ ( n | max ) ]
可变长度 Unicode 字符数据。n 值在 1 到 4,000 之间(含)。max 指示最大存储大小为 2^31-1 字节。存储大小是所输入字符个数的两倍 + 2 个字节。所输入数据的长度可以为 0 个字符。
注释
如果没有在数据定义或变量声明语句中指定 n,则默认长度为 1。如果没有使用 CAST 函数指定 n,则默认长度为 30。
如果列数据项的大小可能相同,请使用 nchar。
如果列数据项的大小可能差异很大,请使用 nvarchar。
sysname 是系统提供的用户定义数据类型,除了不可为空值外,在功能上与 nvarchar(128) 相同。sysname 用于引用数据库对象名。
为使用 nchar 或 nvarchar 的对象分配的是默认的数据库排序规则,但可使用 COLLATE 子句分配特定的排序规则。
SET ANSI_PADDING ON 永远适用于 nchar 和 nvarchar。SET ANSI_PADDING OFF 不适用于 nchar 或 nvarchar 数据类型。
在Oracle中CHAR,NCHAR,VARCHAR,VARCHAR2,NVARCHAR2这五种类型的区别
1.CHAR(size)和VARCHAR(size)的区别
CHAR为定长的字段,最大长度为2K字节;
VARCHAR为可变长的字段,最大长度为4K字节;
2.CHAR(size)和NCHAR(size)的区别
CHAR如果存放字母数字占1个字节,存放GBK编码的汉字存放2个字节,存放UTF-8编码的汉字占用3个字节;
NCHAR根据所选字符集来定义存放字符的占用字节数,一般都为2个字节存放一个字符(不管字符或者汉字)
3.VARCHAR(size)和VARCHAR2(size)的区别
在现在的版本中,两者是没有区别的;最大长度为4K字节;推荐使用VARCHAR2;
4.VARCHAR2(size)和NVARCHAR2(size)的区别
最大长度为4K字节,区别同CHAR与NCHAR的区别;(如果数据库字符集长度是2,则NVARCHAR2最大为2K)
5.共同特性
当执行insert的时候,插入的值为”,则转变成null,即insert … values(”) <=> insert … values(null)
搜索的条件须用where xx is null
6.例子
比如有一个性别字段,里面存放“男,女”的其中一个值,两种常用选择
CHAR(2) 和 NCHAR(1)
这是几个令很多初学者容易混淆的概念。相信很多初学者都与我一样被标题上这些个概念搞得一头雾水。我们现在就来把它们弄个明白。
什么是数据库名?
数据库名就是一个数据库的标识,就像人的身份证号一样。他用参数DB_NAME表示,如果一台机器上装了多个数据库,那么每一个数据库都有一个数据库名。在数据库安装或创建完成之后,参数DB_NAME被写入参数文件之中。格式如下:
DB_NAME=myorcl
…
在创建数据库时就应考虑好数据库名,并且在创建完数据库之后,数据库名不宜修改,即使要修改也会很麻烦。因为,数据库名还被写入控制文件中,控制文件是以二进制型式存储的,用户无法修改控制文件的内容。假设用户修改了参数文件中的数据库名,即修改DB_NAME的值。但是在Oracle启动时,由于参数文件中的DB_NAME与控制文件中的数据库名不一致,导致数据库启动失败,将返回ORA-01103错误。
数据库名的作用
数据库名是在安装数据库、创建新的数据库、创建数据库控制文件、修改数据结构、备份与恢复数据库时都需要使用到的。
有很多Oracle安装文件目录是与数据库名相关的,如:
winnt: d:\oracle\product\10.1.0\oradata\DB_NAME\…
Unix: /home/app/oracle/product/10.1.0/oradata/DB_NAME/…
pfile:
winnt: d:\oracle\product\10.1.0\admin\DB_NAME\pfile\ini.ora
Unix: /home/app/oracle/product/10.1.0/admin/DB_NAME/pfile/init$ORACLE_SID.ora
跟踪文件目录:
winnt: /home/app/oracle/product/10.1.0/admin/DB_NAME/bdump/…
另外,在创建数据时,careate database命令中的数据库名也要与参数文件中DB_NAME参数的值一致,否则将产生错误。
同样,修改数据库结构的语句alter database, 当然也要指出要修改的数据库的名称。
如果控制文件损坏或丢失,数据库将不能加载,这时要重新创建控制文件,方法是以nomount方式启动实例,然后以create controlfile命令创建控制文件,当然这个命令中也是指指DB_NAME。
还有在备份或恢复数据库时,都需要用到数据库名。
总之,数据库名很重要,要准确理解它的作用。
查询当前数据名
方法一:select name from v$database;
方法二:show parameter db
方法三:查看参数文件。
修改数据库名
前面建议:应在创建数据库时就确定好数据库名,数据库名不应作修改,因为修改数据库名是一件比较复杂的事情。那么现在就来说明一下,如何在已创建数据之后,修改数据库名。步骤如下:
1.关闭数据库。
2.修改数据库参数文件中的DB_NAME参数的值为新的数据库名。
3.以NOMOUNT方式启动实例,修建控制文件(有关创建控制文件的命令语法,请参考oracle文档)
什么是数据库实例名?
数据库实例名是用于和操作系统进行联系的标识,就是说数据库和操作系统之间的交互用的是数据库实例名。实例名也被写入参数文件中,该参数为instance_name,在winnt平台中,实例名同时也被写入注册表。
数据库名和实例名可以相同也可以不同。
在一般情况下,数据库名和实例名是一对一的关系,但如果在oracle并行服务器架构(即oracle实时应用集群)中,数据库名和实例名是一对多的关系。这一点在第一篇中已有图例说明。
查询当前数据库实例名
方法一:select instance_name from v$instance;
方法二:show parameter instance
方法三:在参数文件中查询。
数据库实例名与ORACLE_SID
虽然两者都表是oracle实例,但两者是有区别的。instance_name是oracle数据库参数。而ORACLE_SID是操作系统的环境变量。ORACLD_SID用于与操作系统交互,也就是说,从操作系统的角度访问实例名,必须通过ORACLE_SID。在winnt不台,ORACLE_SID还需存在于注册表中。
且ORACLE_SID必须与instance_name的值一致,否则,你将会收到一个错误,在unix平台,是“ORACLE not available”,在winnt平台,是“TNS:协议适配器错误”。
数据库实例名与网络连接
数据库实例名除了与操作系统交互外,还用于网络连接的oracle服务器标识。当你配置oracle主机连接串的时候,就需要指定实例名。当然8i以后版本的网络组件要求使用的是服务名SERVICE_NAME。这个概念接下来说明 。
什么是数据库域名?
在分布工数据库系统中,不同版本的数据库服务器之间,不论运行的操作系统是unix或是windows,各服务器之间都可以通过数据库链路进行远程复制,数据库域名主要用于oracle分布式环境中的复制。举例说明如:
全国交通运政系统的分布式数据库,其中:
福建节点: fj.jtyz
福建厦门节点: xm.fj.jtyz
江西: jx.jtyz
江西上饶:sr.jx.jtyz
这就是数据库域名。
数据库域名在存在于参数文件中,他的参数是db_domain.
查询数据库域名
方法一:select value from v$parameter where name = ‘db_domain';
方法二:show parameter domain
方法三:在参数文件中查询。
全局数据库名
全局数据库名=数据库名+数据库域名,如前述福建节点的全局数据库名是:oradb.fj.jtyz
什么是数据库服务名?
从oracle9i版本开始,引入了一个新的参数,即数据库服务名。参数名是SERVICE_NAME。
如果数据库有域名,则数据库服务名就是全局数据库名;否则,数据库服务名与数据库名相同。
查询数据库服务名
方法一:select value from v$parameter where name = ‘service_name';
方法二:show parameter service_name
方法三:在参数文件中查询。
数据库服务名与网络连接
从oracle8i开始的oracle网络组件,数据库与客户端的连接主机串使用数据库服务名。之前用的是ORACLE_SID,即数据库实例名。